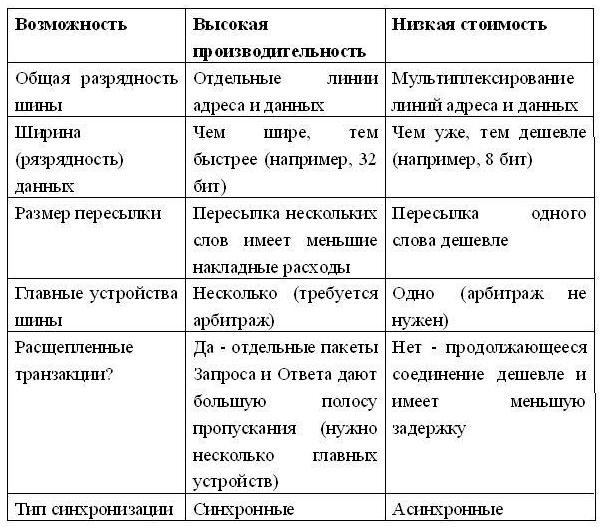
Общие положения В вычислительной системе, состоящей из множества подсистем, необходим механизм для их взаимодействия. Эти подсистемы должны быстро и эффективно обмениваться данными. Например, процессор, с одной стороны, должен быть связан с памятью, с другой стороны, необходима связь процессора с устройствами ввода/вывода. Одним из простейших механизмов, позволяющих организовать взаимодействие различных подсистем, является единственная центральная шина, к которой подсоединяются все подсистемы. Доступ к такой шине разделяется между всеми подсистемами. Подобная организация имеет два основных преимущества: • низкая стоимость; • универсальность. Поскольку такая шина является единственным местом подсоединения для разных устройств, новые устройства могут быть легко добавлены, и одни и те же периферийные устройства можно даже применять в разных вычислительных системах, использующих однотипную шину. Стоимость такой организации получается достаточно низкой, поскольку для реализации множества путей передачи информации используется единственный набор линий шины, разделяемый множеством устройств. Главным недостатком организации с единственной шиной является то, что шина создает узкое горло, ограничивая, возможно, максимальную пропускную способность ввода/вывода. Если весь поток ввода/вывода должен проходить через центральную шину, такое ограничение пропускной способности весьма реально. В коммерческих системах, где ввод/вывод осуществляется очень часто, а также в суперкомпьютерах, где необходимые скорости ввода/вывода очень высоки из-за высокой производительности процессора, одним из главных вопросов разработки является создание системы нескольких шин, способной удовлетворить все запросы. Одна из причин больших трудностей, возникающих при разработке шин, заключается в том, что максимальная скорость шины главным образом лимитируется физическими факторами: • длиной шины, • количеством подсоединяемых устройств. Эти физические ограничения не позволяют произвольно ускорять шины. Требования быстродействия (малой задержки) системы ввода/вывода и высокой пропускной способности являются противоречивыми. В современных крупных системах используется целый комплекс взаимосвязанных шин, каждая из которых обеспечивает упрощение взаимодействия различных подсистем, высокую пропускную способность, избыточность (для увеличения отказоустойчивости) и эффективность. Традиционно шины делятся: • на шины, обеспечивающие организацию связи процессора с памятью, • и шины ввода/вывода. Шины ввода/вывода могут иметь большую протяженность, поддерживать подсоединение многих типов устройств, и обычно следуют одному из шинных стандартов. Шины процессор-память, с другой стороны, сравнительно короткие, обычно высокоскоростные и соответствуют организации системы памяти для обеспечения максимальной пропускной способности канала память-процессор. На этапе разработки системы, для шины процессор-память заранее известны все типы и параметры устройств, которые должны соединяться между собой, в то время как разработчик шины ввода/вывода должен иметь дело с устройствами, различающимися по задержке и пропускной способности. Как уже было отмечено, с целью снижения стоимости некоторые компьютеры имеют единственную шину для памяти и устройств ввода/вывода. Такая шина часто называется системной. Персональные компьютеры, как правило, строятся на основе одной системной шины в стандартах ISA или PCI. Необходимость сохранения баланса производительности по мере роста быстродействия микропроцессоров привела к двухуровневой организации шин в персональных компьютерах на основе локальной шины. Локальной шиной называется шина, электрически выходящая непосредственно на контакты микропроцессора. Она обычно объединяет процессор, память, схемы буферизации для системной шины и ее контроллер, а также некоторые вспомогательные схемы. Типичными примерами локальных шин являются VL-Bus и PCI. Разработка шины связана с реализацией ряда дополнительных возможностей (табл. 1). Таблица 1 Основные возможности шин 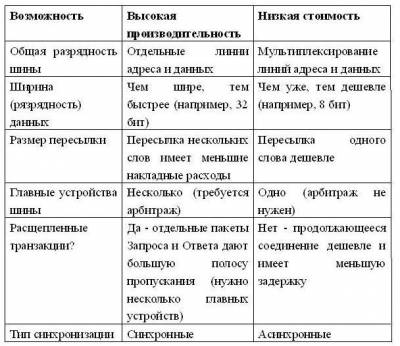
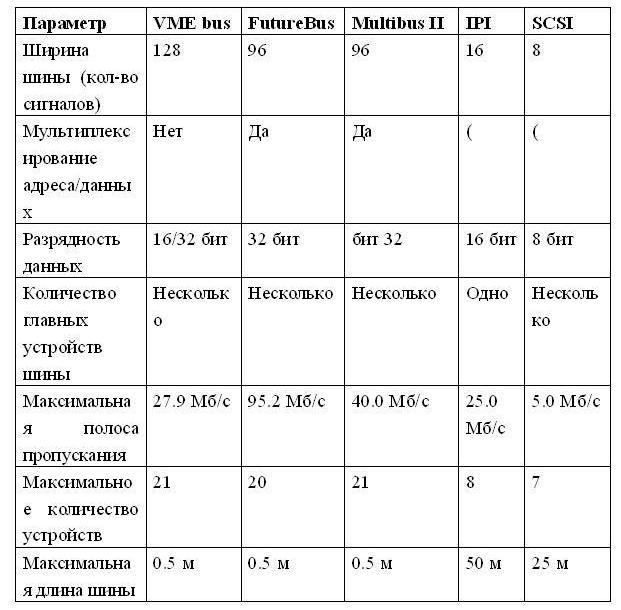
Решение о выборе той или иной возможности зависит от целевых параметров стоимости и производительности. Первые три возможности являются очевидными: • раздельные линии адреса и данных, • более широкие (имеющие большую разрядность) шины данных, • режим групповых пересылок (пересылки нескольких слов) Они дают увеличение производительности за счет увеличения стоимости. Следующий термин, указанный в таблице, - количество главных устройств шины (bus master). Главное устройство шины - это устройство, которое может инициировать транзакции чтения или записи. ЦП, например, всегда является главным устройством шины. Шина имеет несколько главных устройств, если имеется несколько ЦП или когда устройства ввода/вывода могут инициировать транзакции на шине. Если имеется несколько таких устройств, то требуется схема арбитража, чтобы решить, кто следующий захватит шину. Арбитраж часто основан либо на схеме с фиксированным приоритетом, либо на более "справедливой" схеме, которая случайным образом выбирает, какое главное устройство захватит шину. В настоящее время используются два типа шин, отличающиеся способом коммутации: • шины с коммутацией цепей (circuit-switched bus), • шины с коммутацией пакетов (packet-switched bus). Они получившие свои названия по аналогии со способами коммутации в сетях передачи данных. Шина с коммутацией пакетов при наличии нескольких главных устройств шины обеспечивает значительно большую пропускную способность по сравнению с шиной с коммутацией цепей за счет разделения транзакции на две логические части: запроса шины и ответа. Такая методика получила название "расщепления" транзакций (split transaction). (В некоторых системах такая возможность называется шиной соединения/разъединения (connect/disconnect) или конвейерной шиной (pipelined bus). Транзакция чтения разбивается на транзакцию запроса чтения, которая содержит адрес, и транзакцию ответа памяти, которая содержит данные. Каждая транзакция теперь должна быть помечена (тегирована) соответствующим образом, чтобы ЦП и память могли сообщить что есть что. Шина с коммутацией цепей не делает расщепления транзакций, любая транзакция на ней есть неделимая операция. Главное устройство запрашивает шину, после арбитража помещает на нее адрес и блокирует шину до окончания обслуживания запроса. Большая часть этого времени обслуживания при этом тратится не на выполнение операций на шине (например, на задержку выборки из памяти). Таким образом, в шинах с коммутацией цепей это время просто теряется. Расщепленные транзакции делают шину доступной для других главных устройств пока память читает слово по запрошенному адресу. Это, правда, также означает, что ЦП должен бороться за шину для посылки данных, а память должна бороться за шину, чтобы вернуть данные. Таким образом, шина с расщеплением транзакций имеет более высокую пропускную способность, но обычно она имеет и большую задержку, чем шина, которая захватывается на все время выполнения транзакции. Транзакция называется расщепленной, поскольку произвольное количество других пакетов или транзакций могут использовать шину между запросом и ответом. Последний вопрос связан с выбором типа синхронизации и определяет, является ли шина синхронной или асинхронной. Если шина синхронная, то она включает сигналы синхронизации, которые передаются по линиям управления шины, и фиксированный протокол, определяющий расположение сигналов адреса и данных относительно сигналов синхронизации. Поскольку практически никакой дополнительной логики не требуется для того, чтобы решить, что делать в следующий момент времени, эти шины могут быть и быстрыми, и дешевыми. Однако они имеют два главных недостатка. Все на шине должно происходить с одной и той же частотой синхронизации, поэтому из-за проблемы перекоса синхросигналов, синхронные шины не могут быть длинными. Обычно шины процессор-память синхронные. Асинхронная шина, с другой стороны, не тактируется. Вместо этого обычно используется старт-стопный режим передачи и протокол "рукопожатия" (handshaking) между источником и приемником данных на шине. Эта схема позволяет гораздо проще приспособить широкое разнообразие устройств и удлинить шину без беспокойства о перекосе сигналов синхронизации и о системе синхронизации. Если может использоваться синхронная шина, то она обычно быстрее, чем асинхронная, из-за отсутствия накладных расходов на синхронизацию шины для каждой транзакции. Выбор типа шины (синхронной или асинхронной) определяет не только пропускную способность, но также непосредственно влияет на емкость системы ввода/вывода в терминах физического расстояния и количества устройств, которые могут быть подсоединены к шине. Асинхронные шины по мере изменения технологии лучше масштабируются. Шины ввода/вывода обычно асинхронные. Стандарты шин Обычно количество и типы устройств ввода/вывода в вычислительных системах не фиксируются, что позволяет пользователю самому подобрать необходимую конфигурацию. Шина ввода/вывода компьютера может рассматриваться как шина расширения, обеспечивающая постепенное наращивание устройств ввода/вывода. Поэтому стандарты играют огромную роль, позволяя разработчикам компьютеров и устройств ввода/вывода работать независимо. Появление стандартов определяется разными обстоятельствами. Иногда широкое распространение и популярность конкретных машин становятся причиной того, что их шина ввода/вывода становится стандартом де-факто. Примерами таких шин могут служить PDP-11 Unibus и IBM PC-AT Bus. Иногда стандарты появляются также в результате определенных достижений по стандартизации в некотором секторе рынка устройств ввода/вывода. Интеллектуальный периферийный интерфейс (IPI - Intelligent Peripheral Interface) и Ethernet являются примерами стандартов, появившихся в результате кооперации производителей. Успех того или иного стандарта в значительной степени определяется его принятием такими организациями как ANSI (Национальный институт по стандартизации США) или IEEE (Институт инженеров по электротехнике и радиоэлектронике). Иногда стандарт шины может быть прямо разработан одним из комитетов по стандартизации: примером такого стандарта шины является FutureBus. В табл. 2 представлены характеристики нескольких стандартных шин. Заметим, что строки этой таблицы, касающиеся пропускной способности, не указаны в виде одной цифры для шин процессор-память (VME, FutureBus, MultibusII). Размер пересылки, из-за разных накладных расходов шины, сильно влияет на пропускную способность. Поскольку подобные шины обычно обеспечивают связь с памятью, то пропускная способность шины зависит также от быстродействия памяти. Например, в идеальном случае при бесконечном размере пересылки и бесконечно быстрой памяти (время доступа 0 нсек) шина FutureBus на 240% быстрее шины VME, но при пересылке одиночных слов из 150-нсекундной памяти шина FutureBus только примерно на 20% быстрее, чем шина VME. Таблица 2 Примеры стандартных
шин 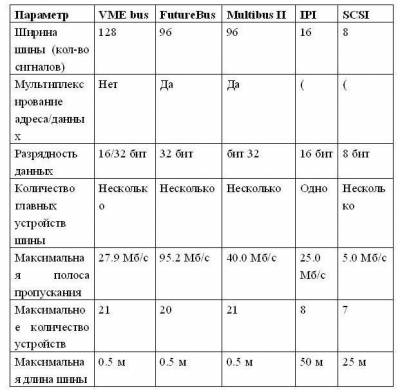
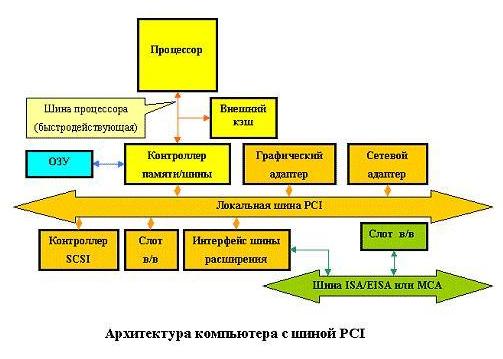
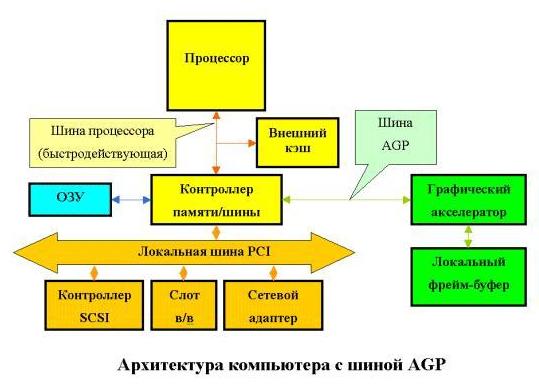
Системная шина IBM PC/XT Одной из популярных шин персональных компьютеров была системная шина IBM PC/XT, обеспечивавшая передачу 8 бит данных. Кроме того, эта шина включала 20 адресных линий, которые ограничивали адресное пространство пределом в 1 Мбайт. Для работы с внешними устройствами в этой шине были предусмотрены также 4 линии аппаратных прерываний (IRQ) и 4 линии для требования внешними устройствами прямого доступа к памяти (DMA). Для подключения плат расширения использовались специальные 62-контактные разъемы. При этом системная шина и микропроцессор синхронизировались от одного тактового генератора с частотой 4.77 МГц. Теоретическая скорость передачи данных могла достигать немногим более 4 Мбайт/с. Системная шина VME Шина VME приобрела большую популярность как шина ввода/вывода в рабочих станциях и серверах на базе RISC-процессоров. Эта шина высоко стандартизована, имеется несколько версий этого стандарта. В частности, VME32 - 32-битовая шина с производительностью 30 Мбайт/с, а VME64 - 64-битовая шина с производительностью 160 Мбайт/с. Шина ввода/вывода SCSI Одной из наиболее популярных шин ввода-вывода является шина SCSI. Под термином SCSI - Small Computer System Interface (Интерфейс малых вычислительных систем) обычно понимается набор стандартов, разработанных Национальным институтом стандартов США (ANSI) и определяющих механизм реализации магистрали передачи данных между системной шиной компьютера и периферийными устройствами. На сегодняшний день приняты два стандарта (SCSI-1 и SCSI-2). Стандарт SCSI-3 находится в процессе доработки. Начальный стандарт 1986 года, известный теперь под названием SCSI-1, определял рабочие спецификации протокола шины, набор команд и электрические параметры. В 1992 году этот стандарт был пересмотрен с целью устранения недостатков первоначальной спецификации (особенно в части синхронного режима передачи данных) и добавления новых возможностей повышения производительности, таких как "быстрый режим" (fast mode), "широкий режим" (wide mode) и помеченные очереди. Этот пересмотренный стандарт получил название SCSI-2 и в настоящее время используется большинством поставщиков вычислительных систем. Первоначально SCSI предназначался для использования в небольших дешевых системах и поэтому был ориентирован на достижение хороших результатов при низкой стоимости. Характерной его чертой является простота, особенно в части обеспечения гибкости конфигурирования периферийных устройств без изменения организации основного процессора. Главной особенностью подсистемы SCSI является размещение в периферийном оборудовании интеллектуального контроллера. Для достижения требуемого высокого уровня независимости от типов периферийных устройств в операционной системе основной машины, устройства SCSI представляются имеющими очень простую архитектуру. Например, геометрия дискового накопителя представляется в виде линейной последовательности одинаковых блоков, хотя в действительности любой диск имеет более сложную многомерную геометрию, содержащую поверхности, цилиндры, дорожки, характеристики плотности, таблицу дефектных блоков и множество других деталей. В этом случае само устройство или его контроллер несут ответственность за преобразование упрощенной SCSI модели в данные для реального устройства. Стандарт SCSI-2 определяет в частности различные режимы: Wide SCSI, Fast SCSI и Fast-and-Wide SCSI. Стандарт SCSI-1 определяет построение периферийной шины на основе 50-жильного экранированного кабеля, описывает методы адресации и электрические характеристики сигналов. Шина данных SCSI-1 имеет разрядность 8 бит, а максимальная скорость передачи составляет 5 Мбайт/сек. Fast SCSI сохраняет 8-битовую шину данных и тем самым может использовать те же самые физические кабели, что и SCSI-1. Он отличается только тем, что допускает передачи со скоростью 10 Мбайт/сек в синхронном режиме. Wide SCSI удваивает либо учетверяет разрядность шины данных (либо 16, либо 32 бит), допуская соответственно передачи со скоростью либо 10, либо 20 Мбайт/сек. В комбинации Fast-and-Wide SCSI возможно достижение скоростей передачи 20 и 40 Мбайт/сек соответственно. Однако поскольку в обычном 50-жильном кабеле просто не хватает жил, комитет SCSI решил расширить спецификацию вторым 66-жильным кабелем (так называемый B-кабель). B-кабель имеет дополнительные линии данных и ряд других сигнальных линий, позволяющие реализовать режим Fast-and-Wide. В реализации режима Wide SCSI предложена также расширенная адресация, допускающая подсоединение к шине до 16 устройств (вместо стандартных восьми). Это значительно увеличивает гибкость подсистемы SCSI, правда приводит к появлению дополнительных проблем, связанных с эффективностью ее использования. Системная шина ISA Системная шина ISA (Industry Standard Architecture) впервые стала применяться в персональных компьютерах IBM PC/AT на базе процессора i286. Эта системная шина отличалась наличием второго, 36-контактного дополнительного разъема для соответствующих плат расширения. За счет этого количество адресных линий было увеличено на 4, а данных - на 8, что позволило передавать параллельно 16 бит данных и обращаться к 16 Мбайт системной памяти. Количество линий аппаратных прерываний в этой шине было увеличено до 15, а каналов прямого доступа - до 7. Системная шина ISA полностью включала в себя возможности старой 8-разрядной шины. Шина ISA позволяет синхронизировать работу процессора и шины с разными тактовыми частотами. Она работает на частоте 8 МГц, что соответствует максимальной скорости передачи 16 Мбайт/с. В настоящее время в PC она заменяется на шину PCI. Системная шина EISA С появлением процессоров i386, i486 и Pentium шина ISA стала узким местом персональных компьютеров на их основе. Новая системная шина EISA (Extended Industry Standard Architecture), появившаяся в конце 1988 года, обеспечивает адресное пространство в 4 Гбайта, 32-битовую передачу данных (в том числе и в режиме DMA), улучшенную систему прерываний и арбитраж DMA, автоматическую конфигурацию системы и плат расширения. Устройства шины ISA могут работать на шине EISA. Шина EISA предусматривает централизованное управление доступом к шине за счет наличия специального устройства - арбитра шины. Поэтому к ней может подключаться несколько главных устройств шины. Улучшенная система прерываний позволяет подключать к каждой физической линии запроса на прерывание несколько устройств, что снимает проблему количества линий прерывания. Шина EISA тактируется частотой около 8 МГц и имеет максимальную теоретическую скорость передачи данных 33 Мбайт/с. В настоящее время широко не используется, вытеснена шиной PCI. Системная шина VL-bus Шина VL-bus, предложенная ассоциацией VESA (Video Electronics Standard Association), предназначалась для увеличения быстродействия видеоадаптеров и контроллеров дисковых накопителей для того, чтобы они могли работать с тактовой частотой до 40 МГц. Шина VL-bus имеет 32 линии данных и позволяет подключать до трех периферийных устройств, в качестве которых наряду с видеоадаптерами и дисковыми контроллерами могут выступать и сетевые адаптеры. Максимальная скорость передачи данных по шине VL-bus может составлять около 130 Мбайт/с. После появления процессора Pentium ассоциация VESA приступила к работе над новым стандартом. В настоящее время широко не используется, вытеснена шиной PCI. Системная шина PCI Шина PCI (Peripheral Component Interconnect) также, как и шина VL-bus, поддерживает 32-битовый канал передачи данных между процессором и периферийными устройствами, работает на тактовой частоте 33 МГц и имеет максимальную пропускную способность 120 Мбайт/с. При работе с процессорами i486 шина PCI дает примерно те же показатели производительности, что и шина VL-bus. Однако, в отличие от последней, шина PCI является процессорно независимой (шина VL-bus подключается непосредственно к процессору i486 и только к нему). Ee легко подключить к различным центральным процессорам. В их числе Pentium, Alpha, R4400 и PowerPC. В связи с этим обстоятельством, а также с переходом на 64 разрядный канал данных она вытиснила шины стандарта VESA с рынка персональных компьютеров. Архитектура компьютера с шиной PCI показана на рис. 1. 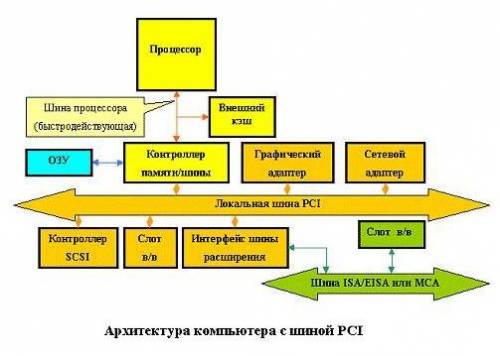 Рис.1. Архитектура компьютера с шиной PCI
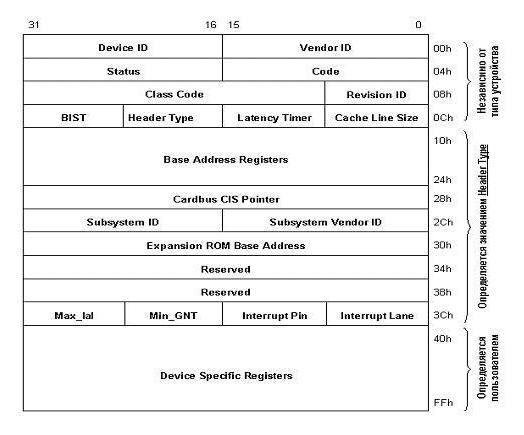
Итак, разработка шины PCI началась весной 1991 года как внутренний проект корпорации Intel (Release 0.1). Специалисты компании поставили перед собой цель разработать недорогое решение, которое бы позволило полностью реализовать возможности нового поколения процессоров 486/Pentium/P6 (вот уже половина ответа). Особенно подчеркивалось, что разработка проводилась "с нуля", а не была попыткой установки новых "заплат" на существующие решения. В результате шина PCI появилась в июне 1992 года (R1.0). Разработчики Intel отказались от использования шины процессора и ввели еще одну "антресольную" (mezzanine) шину. Благодаря такому решению шина получилась, во-первых, процессоро-независимой (в отличие от VLbus), а во-вторых, могла работать параллельно с шиной процессора, не обращаясь к ней за запросами. Например, процессор работает себе с кэшем или системной памятью, а в это время по сети на винчестер пишется информация. Просто здорово! На самом деле идиллии, конечно, не получается, но загрузка шины процессора снижается здорово. Кроме того, стандарт шины был объявлен открытым и передан PCI Special Interest Group, которая продолжила работу по совершенствованию шины (в настоящее время доступен R2.1), и в этом, пожалуй, вторая половина ответа на вопрос "почему PCI?" Основные возможности шины следующие: • Синхронный 32-х или 64-х разрядный обмен данными. При этом для уменьшения числа контактов (и стоимости) используется мультиплексирование, то есть адрес и данные передаются по одним и тем же линиям. • Поддержка 5V и 3.3V логики. Разъемы для 5 и 3.3V плат различаются расположением ключей. • Существуют и универсальные платы, поддерживающие оба напряжения. Заметим, что частота 66MHz поддерживается только 3.3V логикой. • Частота работы шины 33MHz или 66MHz (в версии 2.1) позволяет обеспечить широкий диапазон пропускных способностей (с использованием пакетного режима): 132 МВ/сек при 32-bit/33MHz; 264 MB/сек при 32-bit/66MHz; 264 MB/сек при 64-bit/33MHz; 528 МВ/сек при 64-bit/66MHz. При этом для работы шины на частоте 66MHz необходимо, чтобы все периферийные устройства работали на этой частоте. • Полная поддержка multiply bus master (например, несколько контроллеров жестких дисков могут одновременно работать на шине). • Поддержка write-back и write-through кэша. • Автоматическое конфигурирование карт расширения при включении питания. • Спецификация шины позволяет комбинировать до восьми функций на одной карте (например, видео + звук и т.д.). • Шина позволяет устанавливать до 4 слотов расширения, однако возможно использование моста PCI-PCI для увеличения количества карт расширения. • PCI-устройства оборудованы таймером, который используется для определения максимального промежутка времени, в течении которого устройство может занимать шину. При разработке шины в ее архитектуру были заложены передовые технические решения, позволяющие повысить пропускную способность: Шина поддерживает метод передачи данных, называемый "linear burst" (метод линейных пакетов). Этот метод предполагает, что пакет информации считывается (или записывается) "одним куском", то есть адрес автоматически увеличивается для следующего байта. Естественным образом при этом увеличивается скорость передачи собственно данных за счет уменьшения числа передаваемых адресов. Шина PCI является той черепахой, на которой стоят слоны, поддерживающие "Землю" - архитектуру Microsoft/Intel Plug and Play (PnP) PC architecture. Спецификация шины PCI определяет три типа ресурсов: два обычных (диапазон памяти и диапазон ввода/вывода, как их называет компания Microsoft) и configuration space - "конфигурационное пространство" (рис. 2). 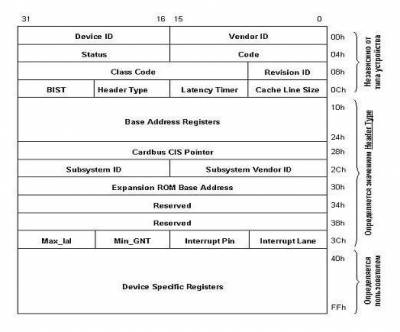 Рис. 2. Конфигурационное пространство.
Конфигурационное пространство состоит из трех регионов: • заголовка, независимого от устройства (device-independent header region); • региона, определяемого типом устройства (header-type region); • региона, определяемого пользователем (user-defined region). В заголовке содержится информация о производителе и типе устройства - поле Class Code (сетевой адаптер, контроллер диска, мультимедиа и т.д.) и прочая служебная информация. Следующий регион содержит регистры диапазонов памяти и ввода/вывода, которые позволяют динамически выделять устройству область системной памяти и адресного пространства. В зависимости от реализации системы конфигурация устройств производится либо BIOS (при выполнении POST - power-on self test), либо программно. Базовый регистр expansion ROM аналогично позволяет отображать ROM устройства в системную память. Поле CIS (Card Information Structure) pointer используется картами cardbus (PCMCIA R3.0). С Subsystem vendor/Subsystem ID все понятно, а последние 4 байта региона используются для определения прерывания и времени запроса/владения. Шина AGP Она имеет следующие существенные отличия от шины PCI: • шина способна передавать два блока данных за один 66 MHz цикл (AGP 2x); • устранена мультиплексированность линий адреса и данных (напомню, что в PCI для удешевления конструкции адрес и данные передавались по одним и тем же линиям); • дальнейшая конвейеризация операций чтения/записи, по мнению разработчиков, позволяет устранить влияние задержек в модулях памяти на скорость выполнения этих операций. В результате пропускная способность шины была оценена в 500 МВ/сек, и предназначена она для того, чтобы видеокарты хранили текстуры в системной памяти, соответственно имели меньше памяти на плате, и, соответственно, дешевели (рис.3). Рис. 3. Архитектура компьютера с шиной AGP.
Парадокс в том, что видеокарты все-таки предпочитают иметь БОЛЬШЕ памяти, и ПОЧТИ НИКТО не хранит текстуры в системной памяти, поскольку текстур такого объема пока (подчеркиваю - пока) практически нет. При этом в силу удешевления памяти вообще, карты особенно и не дорожают. Шина имеет два основных режима работы: Execute и DMA. В режиме DMA основной памятью является память карты. Текстуры хранятся в системной памяти, но перед использованием (тот самый execute) копируются в локальную память карты. Таким образом, AGP действует в качестве "тыловой структуры", обеспечивающей своевременную "доставку патронов" (текстур) на передний край (в локальную память). Обмен ведется большими последовательными пакетами. В режиме Execute локальная и системная память для видеокарты логически равноправны. Текстуры не копируются в локальную память, а выбираются непосредственно из системной. Таким образом, приходится выбирать из памяти относительно малые случайно расположенные куски. Поскольку системная память выделяется динамически, блоками по 4К, в этом режиме для обеспечения приемлемого быстродействия необходимо предусмотреть механизм, отображающий последовательные адреса на реальные адреса 4-х килобайтных блоков в системной памяти. Эта нелегкая задача выполняется с использованием специальной таблицы (Graphic Address Re-mapping Table или GART), расположенной в памяти. При этом адреса, не попадающие в диапазон GART (GART range), не изменяются и непосредственно отображаются на системную память или область памяти устройства (device specific range). На рис. 5 в качестве такой области показан локальный фрейм-буфер карты (Local Frame Buffer или LFB). Точный вид и функционирование GART не определены и зависят от управляющей логики карты. 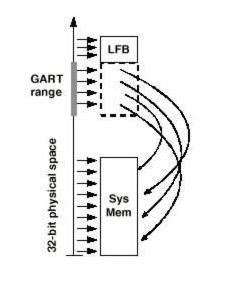 Рис. 5. GART
Шина AGP полностью поддерживает операции шины PCI, поэтому AGP-траффик может представлять собой смесь чередующихся AGP и PCI операций чтения/записи. Операции шины AGP являются раздельными (split). Это означает, что запрос на проведение операции отделен от собственно пересылки данных. Такой подход позволяет AGP-устройству генерировать очередь запросов, не дожидаясь завершения текущей операции, что также повышает быстродействие шины. В 1998 году спецификация шины AGP получила дальнейшее развитие - вышел Revision 2.0. В результате использования новых низковольтных электрических спецификаций появилась возможность осуществлять 4 транзакции (пересылки блока данных) за один 66-мегагерцовый такт (AGP 4x), что означает пропускную способность шины в 1GB/сек. Однако потребности и запросы в области обработки видеосигналов все возрастают, и Intel готовит новую спецификацию - AGP Pro (в настоящее время доступен Revision 0.9) - направленную на удовлетворение потребностей высокопроизводительных графических станций. Новый стандарт не видоизменяет шину AGP. Основное направление - увеличение энергоснабжения графических карт. С этой целью в разъем AGP Pro добавлены новые линии питания.
|  Главная
Главная