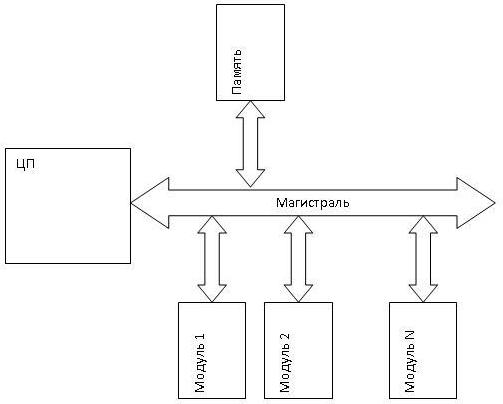
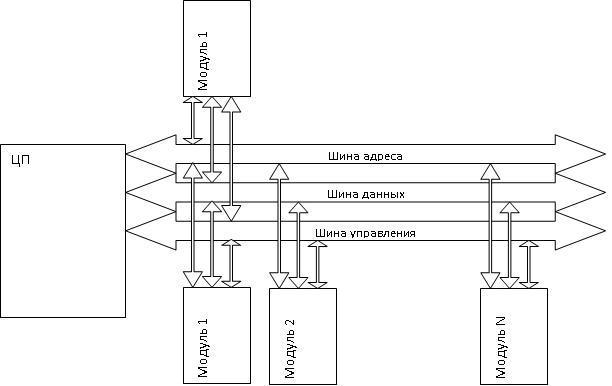
элементы системы могли различать друг друга, каждому из элементов должен быть присвоен некоторый уникальный идентификационный признак. Например, как у людей инициалы.
В качестве уникального механизма используется единая адресная система. Взаимодействие устройств осуществляется через специальные встроенные в них регистры. Каждый регистр в системе имеет уникальный адрес.
Рассмотрим типичную транзакцию на шине. Шинная транзакция включает в себя две части: посылку адреса и прием (или посылку) данных. Шинные транзакции обычно определяются характером взаимодействия с памятью: транзакция типа "Чтение" передает данные из памяти (либо в ЦП, либо в устройство ввода/вывода), транзакция типа "Запись" записывает данные в память.
В транзакции типа "Чтение" по шине сначала посылается в память адрес вместе с соответствующими сигналами управления, индицирующими чтение. Память отвечает, возвращая на шину данные с соответствующими сигналами управления.
Транзакция типа "Запись" требует, чтобы ЦП или устройство в/в послало в память адрес и данные и не ожидает возврата данных. Обычно ЦП вынужден простаивать во время интервала между посылкой адреса и получением данных при выполнении чтения, но часто он не ожидает завершения операции при записи данных в память.
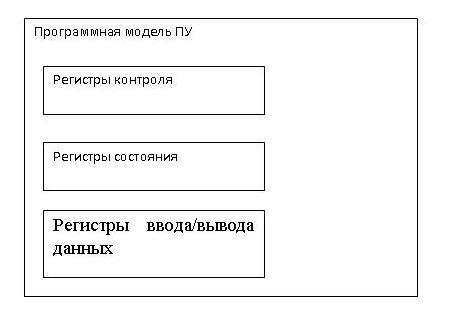
Программная модель ПУ.
Программная модель – это то, как программист видит некоторое периферийное устройство.
Любое ПУ представлено для программиста и программы в виде набора регистров с некоторыми адресами. Все регистры имеют четкое функциональное назначение.
Структурно можно выделить три группы регистров (рис 3.):
1. Регистры контроля.
2. Регистры состояния.
3. Регистры ввода/вывода.
Рис.3. Программная модель абстрактного ПУ.
Занесение некоторого значения в регистры контроля позволяет задать тот или иной режим работы устройства. Обычно в них можно только записать данные, а считать нельзя.
Регистры состояния показывают, в каком состоянии находится ПУ в настоящий момент. Обычно эти регистры можно считать, но записать туда данные нельзя
Через регистры ввода/вывода осуществляется обмен текущей информацией с ПУ.
Пример.
Возьмем в качестве ПУ – адаптер последовательного интерфейса компьютера. Подключим к нему манипулятор-мышь. Настроим его на режим работы, занеся в регистр контроля значение скорости обмена и режима последовательной передачи.
Будем периодически считывать значение регистра состояния, и проверять, полон ли буфер на прием. Когда пользователь изменит положение манипулятора на столе, в последовательный интерфейс поступит информационная посылка с координатами мыши. Она заполнит буфер приема. Когда мы обнаружим этот факт, из регистра вывода мы считаем эту информационную посылку.
Следует обратить внимание, что в зависимости от функциональных свойств ПУ у него может быть несколько регистров контроля, регистров статуса и регистров ввода/вывода. Также возможно совмещение функции некоторых регистров. Например, совмещенный регистр контроля/статуса. Иногда некоторых регистров может не быть.
Виды обмена данными
Программный обмен.
Участники обмена: ЦП и ПУ
Инициатор обмена - ЦП
Алгоритм обмена.
Процессор выставляет на шину адреса значение, соответствующее адресу регистра периферийного модуля.
На шине управления выставляется сигнал на чтение или запись.
По шине данных осуществляется передача данных.
Пример.
Аналогией такого механизма могут служить часы. Хозяин часов сверяет время, когда ему необходимо.
Обмен по прерываниям.
Участники обмена: ЦП, ПУ и контроллер прерываний
Инициатор обмена: ПУ.
Алгоритм обмена.
По возникновению некоторого события ПУ обращается к контроллеру прерываний по специально выделенной линии прерываний на шине управления.
Контроллер прерываний переводит процессор к точке, где расположена программа обработки прерывания. Эта программа осуществляет программное взаимодействие с ПУ.
Пример.
Аналогией такого способа обмена может служить будильник, который звенит не тогда, когда вы проснулись, а когда наступило определенное время.
Возникают вопросы: что будет происходить, если одновременно возникнет два запроса на прерывания от двух разных ПУ, и что делать будет, когда ЦП обрабатывает одно прерывание и возникает другое, более важное и срочное?
Чтобы упорядочить взаимодействие по прерываниям вводится система приоритетов прерываний, то есть иерархия важности прерываний. В зависимости от архитектурных особенностей ЦП и контроллера прерываний есть разных алгоритмы построения приоритетов.
Первый и самый простой – бесприоритетный механизм. В этом случае при возникновении некоторого прерывания никакие другие прерывания не могут быть обработаны до окончания обработки этого прерывания и выстраиваются в очередь обработки.
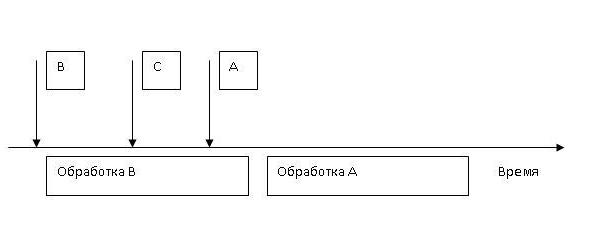
Второй механизм – с относительным приоритетом. В этом случае все прерывания имеют свой приоритет, который у них отличается. Пусть мы имеем три прерывания A,B и С, которые имеют приоритеты а>b>c. Пусть возникло прерывание B. Процессор перешел к программе его обработки. В время обработки возникли запросы на прерывания сначала С, затем А. Обработка прерывания B не была прервана и программа обработки прерывания B доработала до конца. Теперь, несмотря на то, что запрос на прерывание C пришел раньше, чем на A, происходит переход к обработке прерывания A, потому что оно обладает более высоким приоритетом (рис. 4).
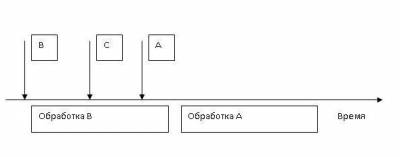
Рис. 4. Обработка прерываний с относительным приоритетом.
Третий механизм – механизм с абсолютным приоритетом. Пусть у нас есть два источника прерывания A и B. С приоритетами a>b. Пусть поступил запрос на прерывание B. Процессор приступил к программе его обработки. В это время поступило прерывание A. Процессор прерывал программу по обработке прерывания B и перешел к обработке прерывания A. По окончании программы обработки прерывания A процессор вернулся и закончил обработку прерывания B.
Рис. 5. Обработка прерываний с абсолютным приоритетом.
В реальных процессорных системах часто смешиваются абсолютный и относительный механизмы приоритетов. В этом случае прерывания объединяются в группы абсолютных приоритетов. Внутри группы действуют относительные приоритеты.
Пример 1.
Пусть система имеет три уровня абсолютных приоритетов 0,1,2.
В каждой группе выделяются по три прерывания:
1. A0,B0,C0 a0>b0>c0
2. A1,B1,C1 a1>b1>c1
3. A2,B2,C2 a2>b2>c2
Тогда между прерываниями A1,B1,C1 действует относительный механизм, а между A2,B1,C0 – абсолютный.
Задача 1.
1. A0,B0,C0 a0>b0>c0 ta0=7мкс tb0=8мкс tc0=9мкс
2. A1,B1,C1 a1>b1>c1 ta1=4мкс tb1=5мкс tc1=6мкс
3. A2,B2,C2 a2>b2>c2 ta2=1мкс tb2=2мкс tc2=3мкс
где t – время на обработку прерыания.
Пусть с некоторого момента времени в системе возникают запросы на прерывания с интервалом в 1мкс в следующей последовательности. С0,B0,A0,C1,B1,A1,C2,B2,A2. В какой последовательности они будут обработаны?
Полинговые системы
В некоторых системах существует сложный механизм динамического изменения прерываний, то есть после выполнения некоторого прерывания его приоритет падает. Такие системы прерываний называются полинговыми. Пусть у нас есть три прерывания A,B,C с динамическими приоритетами a>b>c. Произошло прерывание A, и процессор его обработал. Теперь мы имеем приоритеты b>c>a.
В некоторых случаях приоритет прерывания повышается с течением времени.
Полинговые системы прерываний применяются в системах, где количество прерываний велико или велика частота их возникновения. При статических приоритетах может возникнуть ситуация, когда прерывание с низким приоритетом никогда не будет обработано, так как его постоянно будут вытеснять другие с более высоким приоритетом. Полинговые системы решают эту проблему.
Маскирование прерываний.
Маскирование прерываний – это программный механизм запрета обработки некоторых прерываний. Он осуществляется двумя способами.
Первый запрещает некоторое конкретное прерывание. Обычно это производится путем изменения специального флага в периферийном устройстве, которые запрещает этому устройству выдавать прерывания.
Второй механизм – более общий. Он запрещает ЦП обрабатывать прерывания, приоритет которых ниже заданного.
Пример 2.
Возьмет систему прерываний из более раннего примера:
1. A0,B0,C0
2. A1,B1,C1
3. A2,B2,C2
Запретим ЦП выполнять прерывания ниже 1 уровня. Запретим ПУ выдавать запрос на прерывание B1. Тогда будут обрабатываться прерывания A2,B2,C2,A1,C1.
Задача 2.
Пусть мы имеем эту же систему прерываний. Запретим ПУ выдавать запросы на A0,C1,B2. Запретим ЦП выполнять все прерывания ниже нулевого уровня, ниже первого, ниже второго. Какие в этих случаях прерывания будут обрабатываться?
Часто существует группа прерываний с наивысшим приоритетом, который нельзя запретить. Такие прерывания называются немаскируемыми. Соответственно, прерывания, которые можно запретить, называются маскируемыми.
Примеры прерываний.
Маскируемые:
1. Прерывание от таймера.
2. Прерывание по нажатию клавиши.
3. Прерывание по движению мыши.
Немаскируемые:
1. Прерывание по недопустимому коду операции.
2. Переполнение стека.
Перезапуск процессора тоже является особым видом немаскируемого прерывания, которое называется RESET (сброс).
Обмен по прямому доступу к памяти.
Участники обмена: ПУ, память контроллер прямого доступа к памяти (КПДП или DMA (Direct Access Memory))
Инициатор обмена – ЦП
Такой механизм обмена позволяет ПУ производить запись или чтение данных, минуя ЦП. Это позволяет экономить вычислительные ресурсы системы и повышать ее производительность.
Алгоритм обмена.
ПУ по шине управления выдает запрос на чтение/запись по ПДП. КПДП проверяет не занята ли шина ЦП и информирует его о необходимости занять шину. Когда ЦП освобождает магистраль, КПДП копирует данные из/в ПУ в/из память.
В зависимости от вида ПУ и задач, которые оно решает, КПДП может быть запрограммирован на единичных или блочный обмен данными.
На каждый запрос в КПДП выделяется канал обмена. Так как таких число таких каналов ограниченно, то и количество ПУ, которые могут использовать этот механизм обмена тоже ограниченно.
По окончании обмена КПДП может выступать источником прерываний.
В ранних ПК контроллер прерываний и КПДП использовались в виде отдельных микросхем. С ростом интеграции они переместились на кристалл ЦП.
 Главная
Главная